Prompting: Better Ways of Using Language Models for NLP Tasks
A review of recent advances in prompts.
Starting from BERT (Devlin et al., 2019), fine-tuning pre-trained language models (LMs) with task-specific heads on downstream applications has become standard practice in NLP. However, the GPT-3 model with 175B parameters (Brown et al., 2020) has brought a new way of using LMs for downstream tasks: as the title “Language Models are Few-Shot Learners” suggests, GPT-3 can well handle a wide range of tasks with only a few examples by leveraging natural-language prompts and task demonstrations as context, while not updating the parameters in the underlying model. The giant model size of GPT-3 is an important factor for its success, while the concept of prompts and demonstrations also gives us new insights about how we can better use language models.
So what is a prompt? A prompt is a piece of text inserted in the input examples, so that the original task can be formulated as a (masked) language modeling problem. For example, say we want to classify the sentiment of the movie review “No reason to watch”, we can append a prompt “It was” to the sentence, getting “No reason to watch. It was”. It is natural to expect a higher probability from the LM to generate “terrible” than “great” then.
After the release of GPT-3, many prompt-related papers emerged, and many of them have discussed prompt-based learning for medium-sized pre-trained models like BERT (BERT-base has 110M parameters, 1000x smaller than the largest GPT-3). In this blog post, I will provide an overview of recent prompt-based methods and my perspective of prompting. At the end of it, I am going to introduce our ACL’21 paper, “Making Pre-trained Language Models Better Few-shot Learners.”
Why we want prompts
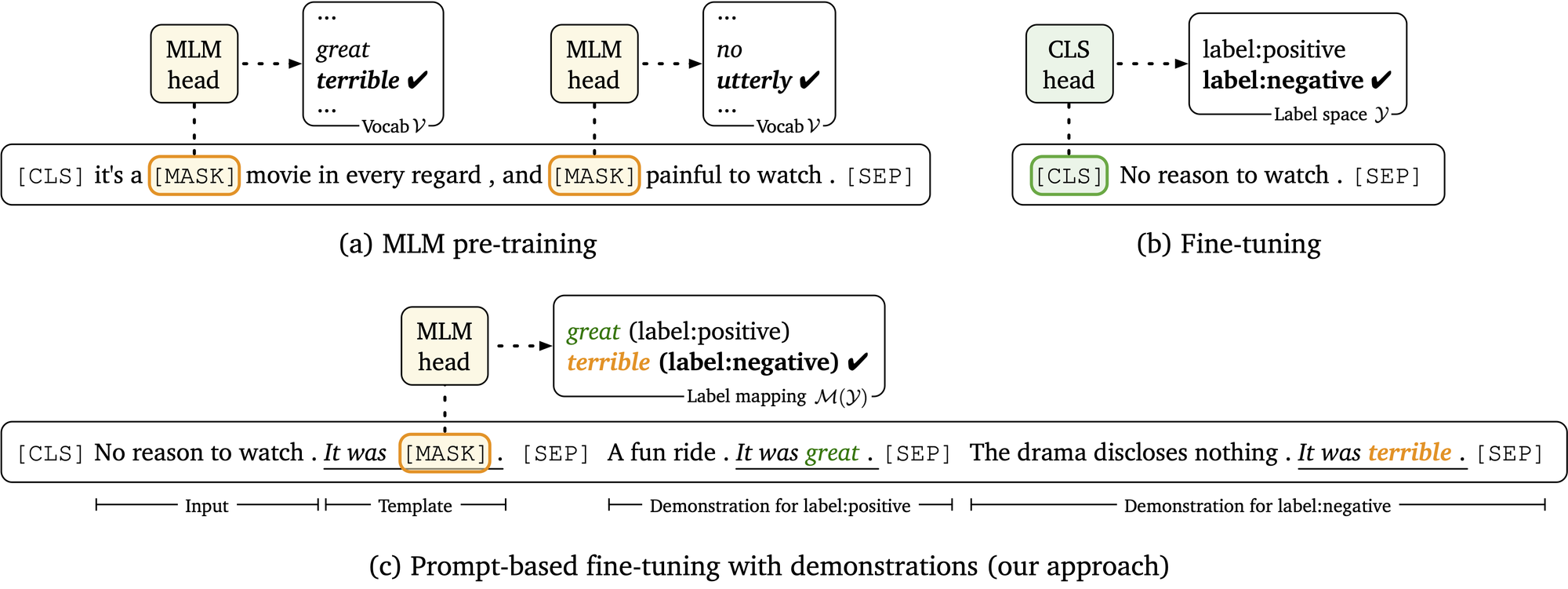
An illustration for pre-training, standard fine-tuning and prompt-based fine-tuning with demonstrations, taking a sentiment classification task as an example (from Gao et al., 2021).
In the standard “pre-training and fine-tuning” paradigm, the gap between the pre-training stage and the downstream task can be significant: the objectives are different, and for the downstream tasks, we usually need to introduce new parameters—for example, for a BERT-large model and a binary classification task, it requires an additional set of 1,024 x 2 parameters. On the other hand, prompting makes it possible for downstream tasks to take the same format as the pre-training objectives, as illustrated in the above figure, and requires no new parameters. For a classification task, we just need to design a template (“It was”) and the expected text responses (we call these label words, e.g., “great” for the positive label and “terrible” for the negative label in the figure). By closing the gap between the two stages, deploying the pre-trained models on specific tasks becomes much easier, especially for the few-shot case—when you only have a dozen of training examples for a new task, it is hard to fine-tune the pre-trained models and the new task-specific parameters effectively, but the process is much smoother with prompting. Scao and Rush (2021) show that a prompt may be worth 100 conventional data points, suggesting that prompts can bring a giant leap in sample efficiency.
There are two different paradigms in the research of prompts, and they share different views: Inspired by the PET papers (Schick and Schütze, 2021a, b), prompt-based fine-tuning (the critical point is that we still further optimize the parameters) is regarded as a path towards better few-shot learners for small language models (by small, I mean millions instead of billions of parameters, like BERT or RoBERTa); For super-large models like 175B GPT-3 and 11B T5 (Raffel et al., 2020), since fine-tuning them is hard (this is just my guess, and I never had the chance to do so) and also costly, it is expected instead to fix their parameters and apply them to different tasks by different prompts (either discrete ones or soft ones, which I will talk about later).
Discrete prompts
The earliest work of using prompts in pre-trained models traces back to GPT-1/2 (Radford et al., 2018, 2019), where the authors show that by designing appropriate prompts, LMs can achieve decent zero-shot performance on tasks from sentiment classification to reading comprehension. Later, Petroni et al. (2019); Davison et al. (2019); Jiang et al. (2020); Talmor et al. (2020) explore utilizing prompts to mine factual or commonsense knowledge from LMs. After GPT-3 took prompts while fixing the parameters, prompt-based methods were further introduced to smaller LMs (Schick and Schütze, 2021a, b; our work LM-BFF, Gao et al., 2021). They differ from GPT-3 in that they fine-tune the full model and take bidirectional masked LMs instead of unidirectional LMs. Several recent papers follow this line of approaches by adjusting the objective (Tam et al., 2021) or formulating tasks in a unified form, like question answering (Zhong et al., 2021a) or textual entailment (Wang et al., 2021). With a comprehensive study of different variants, Logan et al. (2021) show that when taking prompt-based fine-tuning (instead of freezing all the parameters), the model can also achieve better performance than standard fine-tuning without prompts (but a good prompt still makes significant differences), and tuning only part of the model parameters—for example, taking a recently-proposed bias tuning method (Ben-Zaken et al., 2021)—is comparable to full model fine-tuning in the few-shot setting.
In all those models, prompts are in natural language and are composed of discrete tokens from the vocabulary. Most of the work takes manually-designed prompts—prompt engineering is non-trivial since a small perturbation can significantly affect the model’s performance, and creating a perfect prompt requires both understanding of LMs’ inner workings and trial-and-error.
In contrast to manually-designed prompts, one can also generate or optimize the prompts: Guo et al., 2021 show a soft Q-learning method that works well for prompt generation; AutoPrompt (Shin et al., 2020) proposes taking a gradient-based search (the idea was from Wallace et al., 2019, which aims for searching a universal adversarial trigger to make a model generate a specific prediction) to find out the best prompt for particular tasks. The setting for AutoPrompt is different in that it fixes the models: it just assumes that everything is encoded in the pre-trained models and all we need is to “prompt” it out; another reason is that AutoPrompt also aims for LAMA (Petroni et al., 2019), a knowledge probing task, where it is required not to touch the model parameters. Below is an example of AutoPrompt used in sentiment classification.
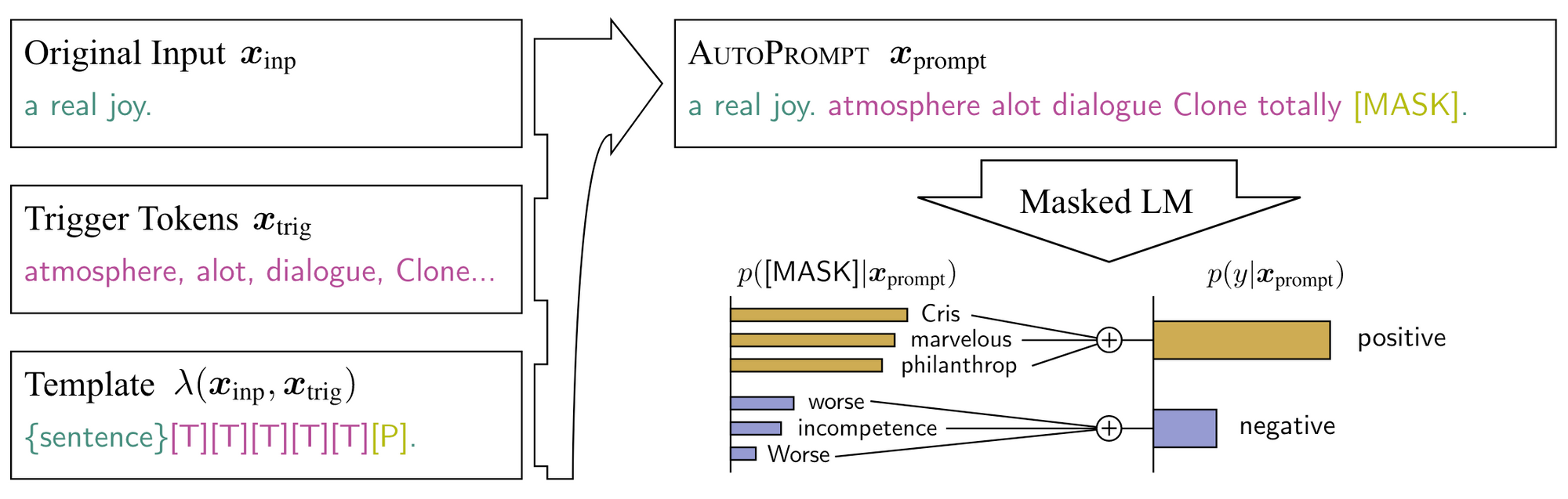
An illustration of AutoPrompt (Shin et al., 2020).
The searched templates considerably improve the LAMA performance; they also achieve surprising accuracies in sentiment classification and natural language inference tasks using the full dataset (still, lower than the fine-tuning paradigm). Taking a look at the searched discrete (but not natural-language anymore) prompts, you can find explanations for some of the “trigger tokens”, but many others are just peculiarities. It is not clear that whether the auto prompt really helps the LMs recall the “knowledge” inside or it is just an alternative way for optimization, picking the “winning tickets” from “lotteries” in the pre-trained models (for the lottery ticket hypothesis, see Frankle and Carbin, 2019).
Soft prompts: do we really need discrete words in the prompts?
Since AutoPrompt already does the gradient-based search for prompts, why not move on from discrete tokens to continuous “soft prompts”? For example, Zhong et al. (2021b) and Qin and Eisner (2021) propose to use “soft prompts” for knowledge probing tasks (LAMA etc.) and have achieved considerable improvements over discrete prompts. The idea is so simple—just putting some random vectors (not tied to specific word embeddings from the vocabulary) in the input sequence and tuning them, with other parts of the pre-trained models fixed.
There is also work deploying soft prompts beyond probing tasks: Li and Liang (2021) extend the idea to generation tasks and show that it performs on par with fine-tuning while only tuning 0.1% parameters. Han et al. (2021) combine soft prompts with manual templates and have achieved supreme performance in relation extraction. The most comprehensive study on soft prompts I have seen till now comes from Lester et al. (2021): they apply soft prompt on T5 and show that by just tuning the prompt (which only takes a tiny proportion of the total parameters), T5 can achieve on par performance on NLU tasks with fine-tuning the whole model. I also like the paper for that it carries out an extensive ablation study and shows several crucial empirical choices for successful soft prompts, including initialization from word embeddings, enough numbers of soft prompt tokens, and an aligned pre-training objective. Besides parameter efficiency, Lester et al. (2021) also demonstrate that the soft prompt delivers better transferability than full model fine-tuning.
Let’s review the idea of soft prompts: it works amazingly well and is especially effective when you cannot (probing tasks) or would not (the model is too large or you want a universal model for all tasks) touch the models’ parameters. Tuning soft prompts is very different from prompt-based fine-tuning, which allows one to optimize the full model and, more importantly, handle few-shot cases much better than standard fine-tuning. Unlike its manual counterpart, AutoPrompt does not work well in the few-shot case, and to the best of my knowledge, no soft-prompt papers argue that they achieve superb few-shot performance (though Liu et al. (2021) showed satisfying few-shot results by starting from discrete manual prompts and fine-tuning the whole model). Also, as Lester et al. (2021) demonstrate, soft prompts never achieve the same performance as full fine-tuning on SuperGLUE until using pre-trained models with more than 10 billion parameters! I believe it is worth investigating how to push soft prompts further to work more effectively in few-shot cases and smaller language models.
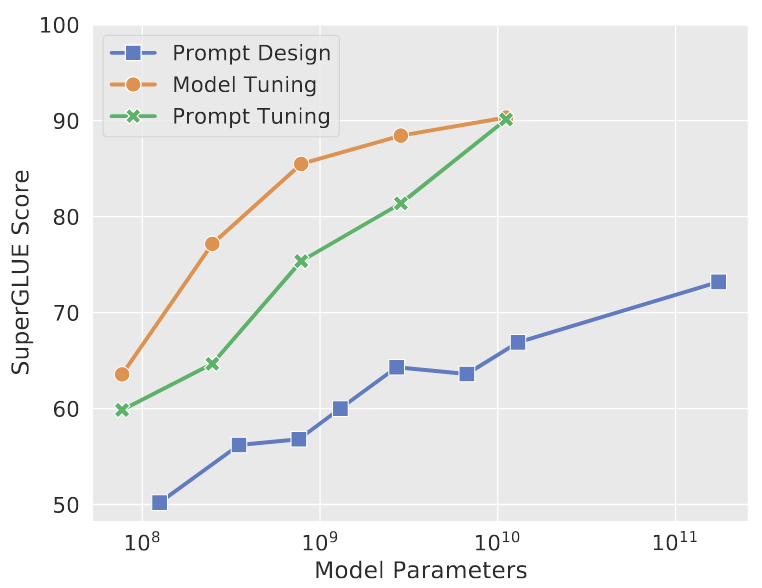
GPT-3 (blue) vs full model fine-tuning (orange) vs soft-prompt tuning (green). Credit to Lester et al. (2021).
In-context learning: a new form of meta-learning
I attribute GPT-3’s success to two model designs at the beginning of this post: prompts and demonstrations (or in-context learning), but I haven’t talked about in-context learning until this section. Since GPT-3’s parameters are not fine-tuned on downstream tasks, it has to “learn” new tasks in an alternative way—through context.

GPT-3 "learns" about new tasks through demonstrations in the context (Brown et al., 2020).
As shown in the above figure, GPT-3 simply concatenates some random examples from the training set with the actual query (“cheese ⇒” in this example), and since the pre-trained model already learns to capture the patterns from the context and Transformers’ self-attention allows token-by-token comparison across these instances, in-context learning works surprisingly well. The GPT-3 paper calls it “meta-learning”, arguing that after reading a large amount of unsupervised text, a language model can “develop a broad set of skills and pattern recognition abilities.” The authors assume that there are “sometimes repeated sub-tasks embedded within a single sequence” during pre-training, similar to the paradigm of in-context learning. Following-up works further refine the way of using demonstrations: Gao et al., 2021; Liu et al. (2021) say that instead of randomly sampling some examples, taking in-context demonstrations similar to the query can substantially improve the performance; Lu et al. (2021) show that even the order of the demonstrations matters a lot and propose a way to determine the “optimal” order.
Although in-context learning is only “necessary” when you cannot tune the model, and it is hard to generalize when the number of training examples increases (because the input length of the model is limited), studying how to better use demonstrations (i.e., how to further squeeze “meta-knowledge” learned by LMs) and what pre-training objectives and data can boost in-context abilities may further help us understand pre-trained LMs’ inner workings.
Calibrating language models
Prompting is great, but it can also bring bias from the pre-training corpora. For example, in a zero-shot sentiment classification setting, given “N/A” as the input, GPT-3 tends to predict “positive” over “negative”, while it is expected to assign 50/50 probabilities to the two contrastive labels (Zhao et al., 2021). Another problem is that different surface forms of the same object (e.g., “computer” and “PC”) may compete for the probability mass, leading to undesirable distributions over task labels (Holtzman et al., 2021). The solution given by Zhao et al. (2021) and Holtzman et al. (2021) is calibration: adding compensation to the biased tokens so that they are calibrated to an unbiased status.
What is a true few-shot setting?
There are many discussions about the few-shot setting itself: it is well known that fine-tuning on small datasets can suffer from instability (Dodge et al., 2020; Zhang et al., 2021), and different splits of data may affect the performance drastically. Previous works take on various settings, but to account for the large variance in few-shot, multiple sampled few-shot data splits and multiple trials with different seeds are needed to deliver a rigorous and faithful few-shot evaluation (which is what we did in our work). Another problem that is constantly neglected is that one cannot assume a large development set in the few-shot case. To cope with that, Schick and Schütze (2021) take no dev set and adopt fixed hyper-parameters (which is akin to “shooting in the dark” in such a fluctuating setting and could have unintuitive outcomes), and in our work, we sample a few-shot dev set with the same size as the training set, so we can tune hyper-parameters while keeping it “few-shot”.
In a recent paper, Perez et al. (2021) argue that prior work overestimates the few-shot performance of LMs by more or less taking many held-out examples for hyper-parameter tuning, model development or prompt design, and they advocate for a “true few-shot learning” setting. This is consistent with our view that you can only assume few-shot dev examples. However, in the real-world case, one can hardly achieve “true few-shot learning”, for you need an adequate amount of held-out examples to verify that your model is valid on at least one or two tasks. It is a good few-shot model as long as the design can generalize well to other few-shot tasks (these tasks can be so-called “true few-shot”). In our work, we take SST-2 and SNLI for the pilot experiments, and show that our method can well generalize to 13 other NLU tasks.
Introducing LM-BFF
Finally, let me introduce our ACL’21 paper, “Making Pre-trained Language Models Better Few-shot Learners”, abbreviated as LM-BFF (better few-shot fine-tuning of language models; alternatively, language models’ best friends forever). LM-BFF is a suite of simple techniques combined for fine-tuning pre-trained LMs on only a small number of training examples, including
- Prompt-based fine-tuning, along with a novel method for automatic prompt generation;
- A dynamic and selective method for incorporating demonstrations in context.
We evaluate LM-BFF in a rigorous few-shot setting (as mentioned above) and show that LM-BFF can drastically outperform standard fine-tuning by up to 30% absolute improvement (on SNLI) and 11% on average. You can find our code at this github repo.
Prompt-based fine-tuning
I have already discussed what prompt-based fine-tuning is—formulating the task as a (masked) language modeling problem with templates and setting the expected output for each class as label words. We design manual templates and labels words as listed below.
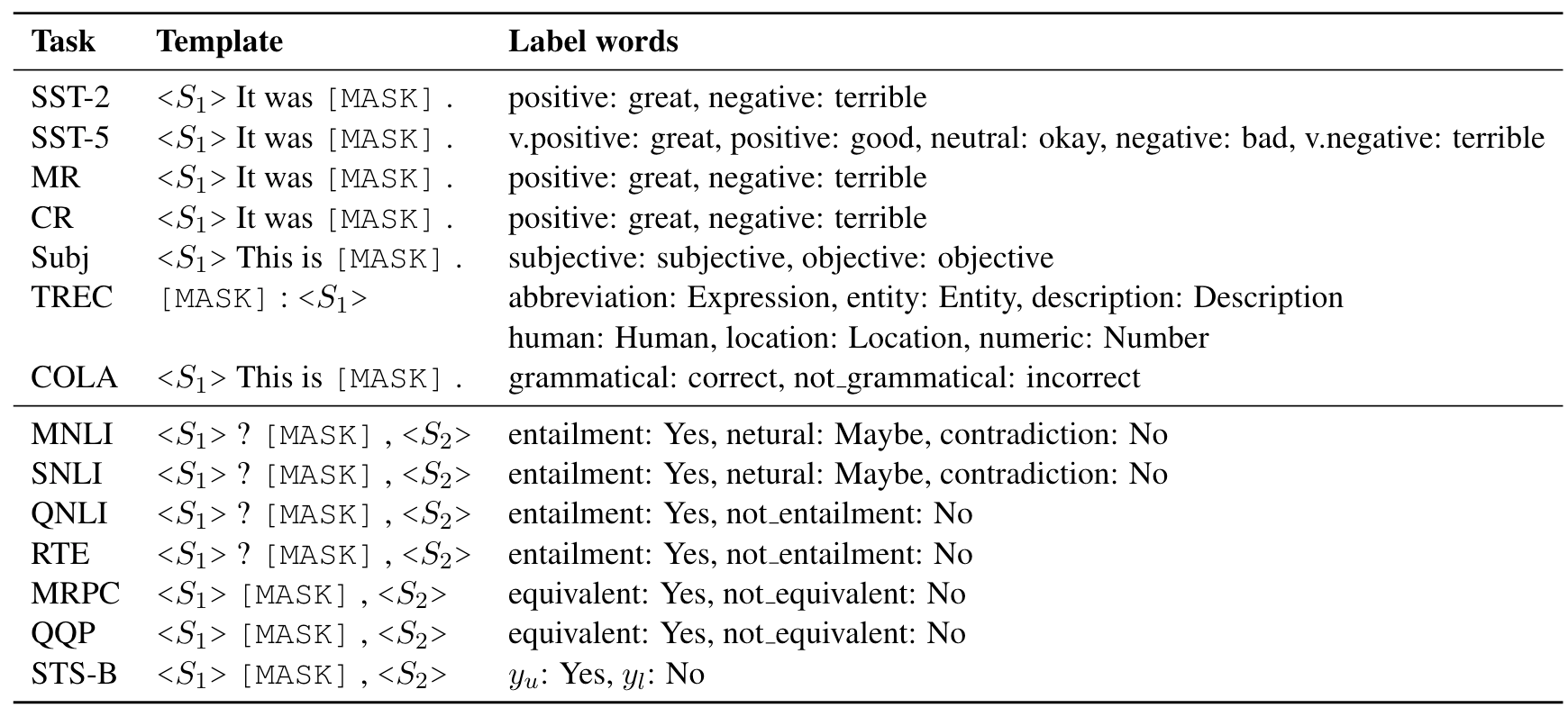
Manual prompts (templates + label words) used in our experiments. S1 and S2 represent the input sentences.
However, hand-crafting good prompts can be tricky, requiring domain expertise, and the outcome can be unintuitive. In the following table, we show how sensitive few-shot models are to the small perturbations in the prompt.
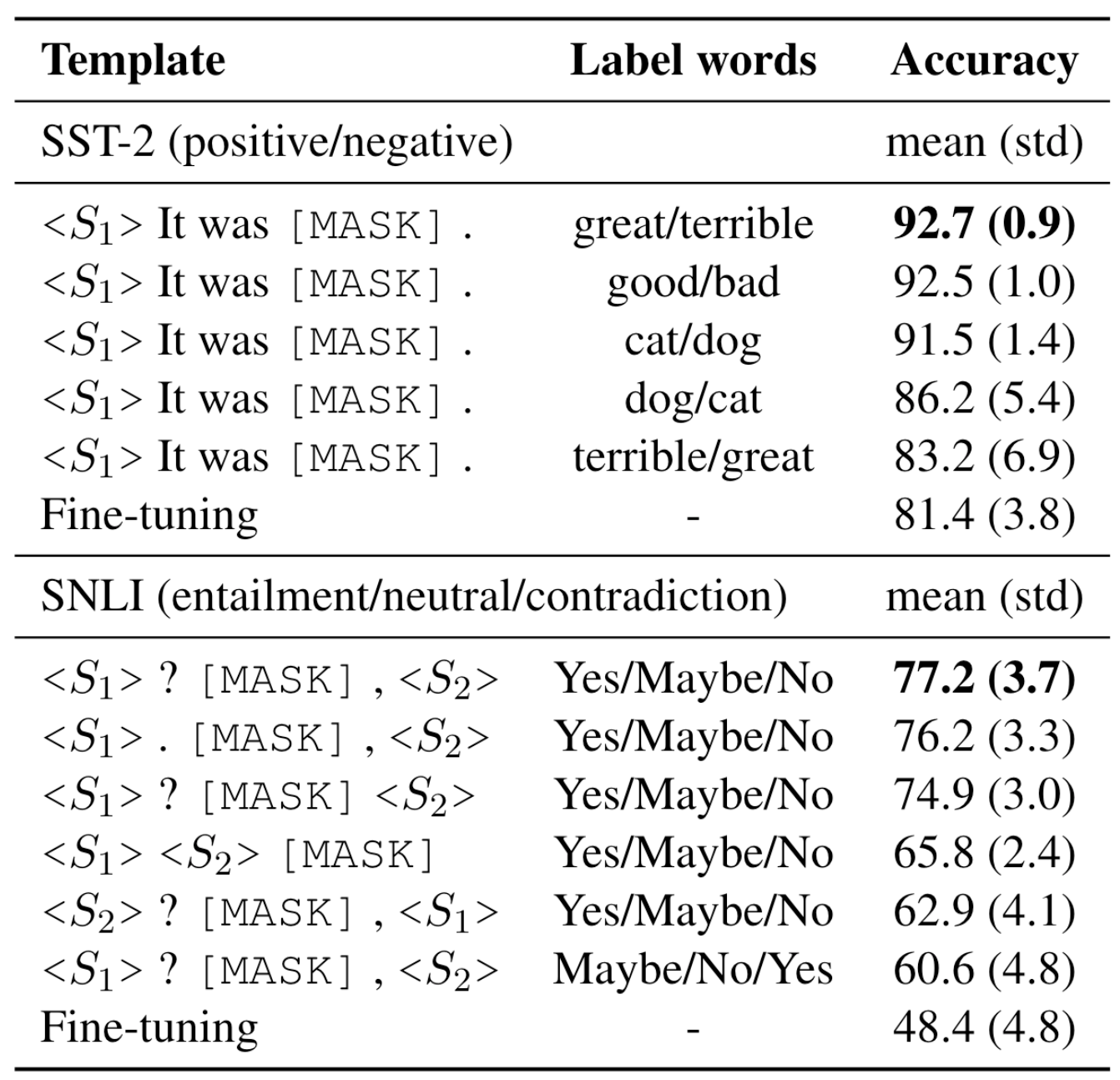
The impact of different templates and label words. We take RoBERTa-large (Liu et al., 2019) and 16 train/dev examples for each class.
We observe that if the template is fixed, the better the label words match the “semantic classes”, the better the result is. For example, for SST-2, great/terrible > good/bad > cat/dog > dot/cat > terrible/good (although it’s unclear why RoBERTa thinks 🐱 is more positive than 🐶). From SNLI, we see that if we put [MASK] at the end or swap the two sentences, there could be a >10% performance drop. This urges us to find a better way beyond manual prompts—automatic prompt search.
Automatic prompt search
We separate the automatic prompt search into two parts—automatically searching label words and searching templates.
For automatic label word search, our goal is to find a set of label words that can maximize the dev performance, given a manual template. A naive way to do so is to brute-force search all combinations of words. However, it does not work since the search space is exponential in the number of classes, and the method is prone to uncover spurious correlations and overfit. Instead, we first construct a candidate word set $V^c$ for each class $c$: denote $D_{train}^c$ as all the training examples with class $c$, we find the top-k words that maximize the LM probability at [MASK] given the template and $D_{train}^c$. Then we enumerate all word combinations of $V_c$ and find the top-n combinations that maximize zero-shot accuracy on the training set. In the end, we fine-tune all the n combinations and rerank them by the dev performance. We find that both brute-force search in the pruned space and the fine-tuning reranking are quite helpful regarding the final performance.
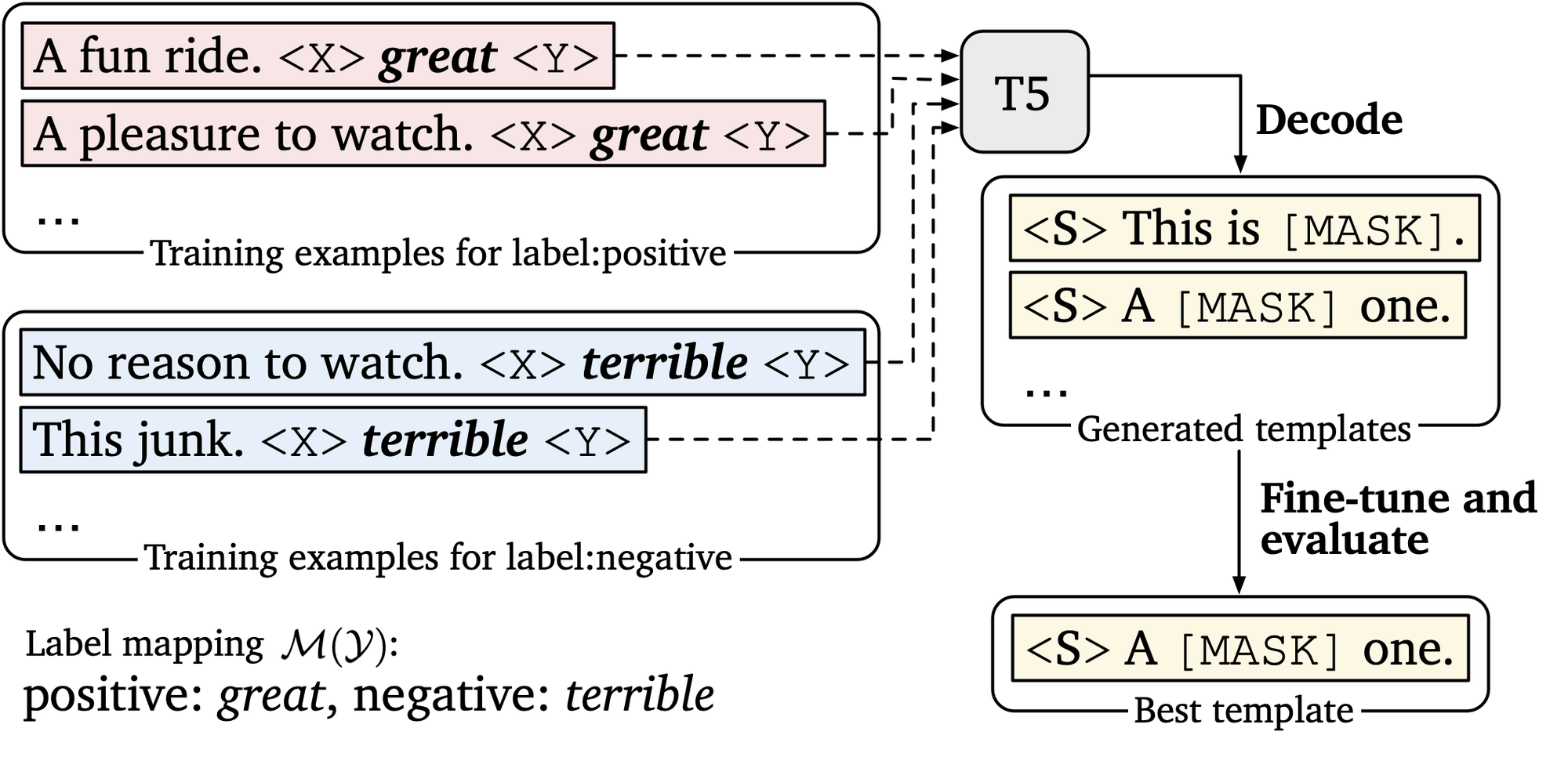
Our approach for template generation.
For automatic template search, the goal is similar: find the template that maximizes the dev accuracy, given the manual label words. We use T5 to generate many template candidates in an out-of-the-box manner, and then rerank them by fine-tuning and dev performance. T5 is a seq-to-seq model and is pre-trained with a fill-in-the-blank objective, making it perfect for generating the template. Take sentiment classification (figure above) as an example, we concatenate the input example and the corresponding label word, and insert
The table below shows some examples generated by our automatic prompt search. You can see that for automatic template search, most templates fit the context and the manual label words well, although there are some potentially biased ones (e.g., “no” in SNLI templates). Although mostly looking intuitive, the label-word results do contain some mysterious abnormalities (e.g., “Hi” for the entailment class in SNLI).
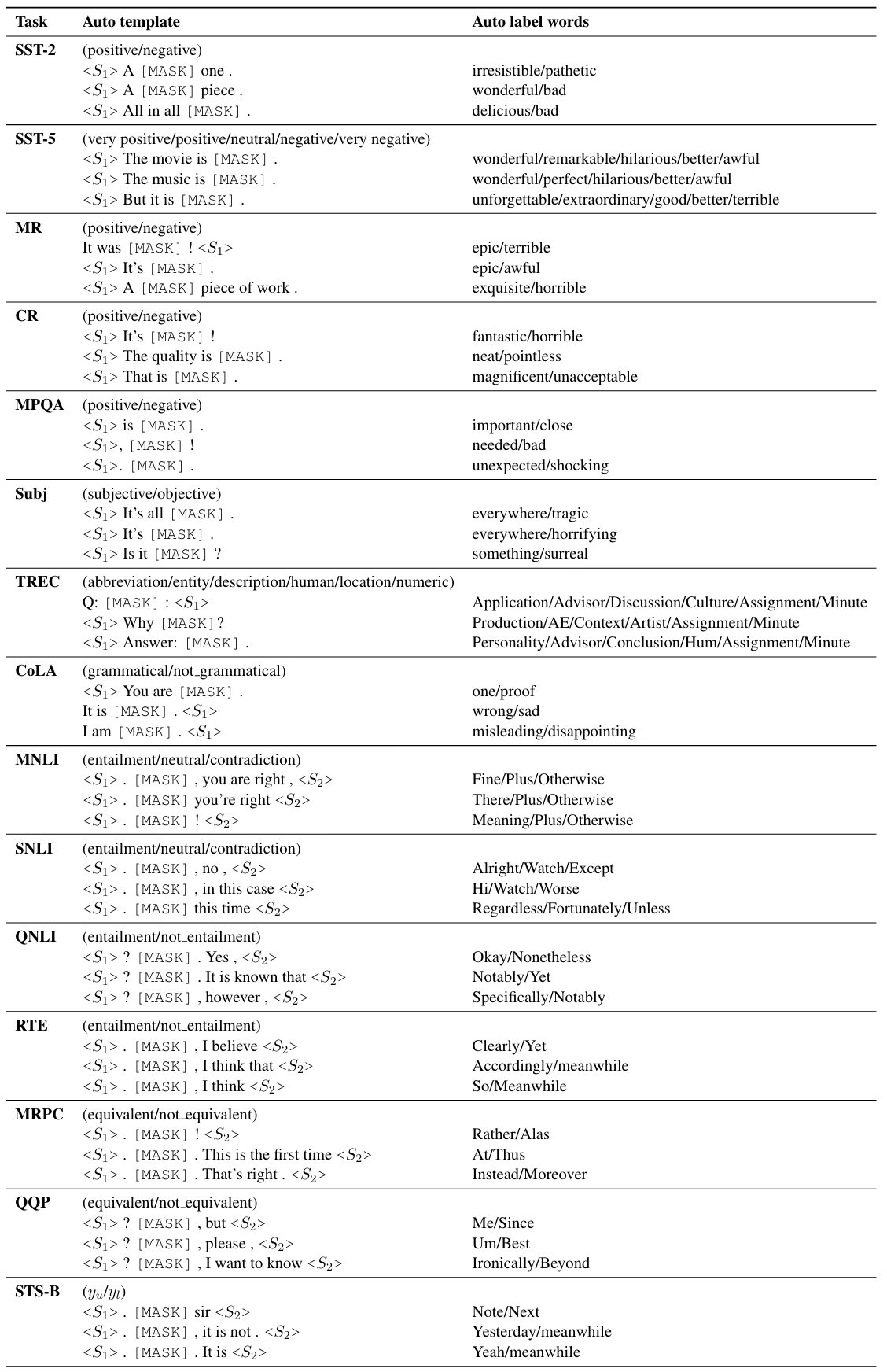
Automatic prompt search results.
Incorporate demonstrations
I have introduced how GPT-3 uses demonstrations in context: randomly sampling examples from the training set and concatenating them in arbitrary order, which is problematic in many aspects: the input lengths of pre-trained LMs are limited, especially for smaller ones (usually 512); it is hard to grasp meaningful patterns if the examples are concatenated in random orders; demonstrations that look far dissimilar to the input instance may be unhelpful or even cause confusion. Thus we propose this dynamic and selective way of incorporating demonstrations:
- During both training and inference, we randomly sample one example for each class from the training set and concatenate them (the first figure in this post gives an example). For inference, we sample multiple sets of demonstrations and ensemble the results in the end.
- We only sample demonstrations that are closely related to the input. For example, if the input is a movie review, then sampling a movie review is much more helpful than a restaurant review. We take SBERT (Reimers and Gurevych, 2019) to encode the sentences, calculate the cosine similarities between the input and all the examples from the training set, and only sample from the top 50% examples.
Results
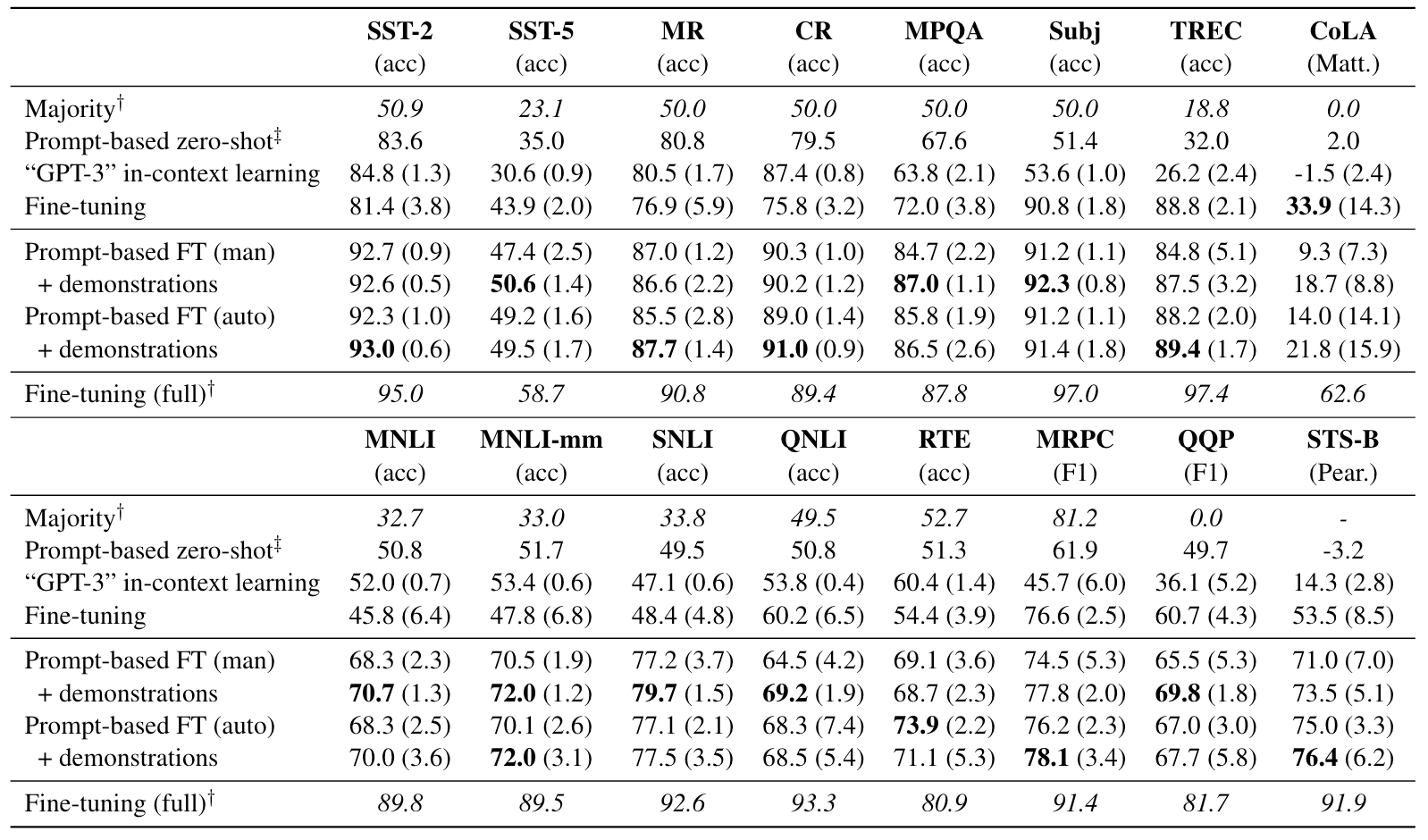
Our main results (RoBERTa-large; each class has 16 training examples; results (standard deviation) are averaged over five splits). "GPT-3" in-context learning: use demonstrations in the GPT-3 style, but still take the fixed RoBERTa-large model. FT: fine-tuning; man: manual; auto: automatic templates.
The above table shows our main experimental results. Here are the main takeaways:
- Using prompts is great, even in the zero-shot case. Also, GPT-3 style learning does not constantly improve the results over the zero-shot model, suggesting that fine-tuning is still needed.
- Prompt-based fine-tuning is much better than standard fine-tuning, with either manual or automatic prompts. On many tasks, automatic templates can get better results than manual ones.
- Incorporating demonstrations can further bring significant improvement, showing that even with fine-tuning, adding demonstrations in context can help with the few-shot tasks.
We also have many interesting experiments in the paper, showing how automatic prompt generation can be combined with ensemble, and how different demonstration and automatic prompt policies affect the performance. In the end, we show that how the comparison between standard fine-tuning and LM-BFF goes with different numbers of training examples. As it clearly demonstrates, LM-BFF almost saturates its performance on simple tasks like SST-2 with only 32 training examples, and on harder tasks like SNLI, it brings a clear advantage over fine-tuning consistently, until the two converge with nearly one thousand training examples.
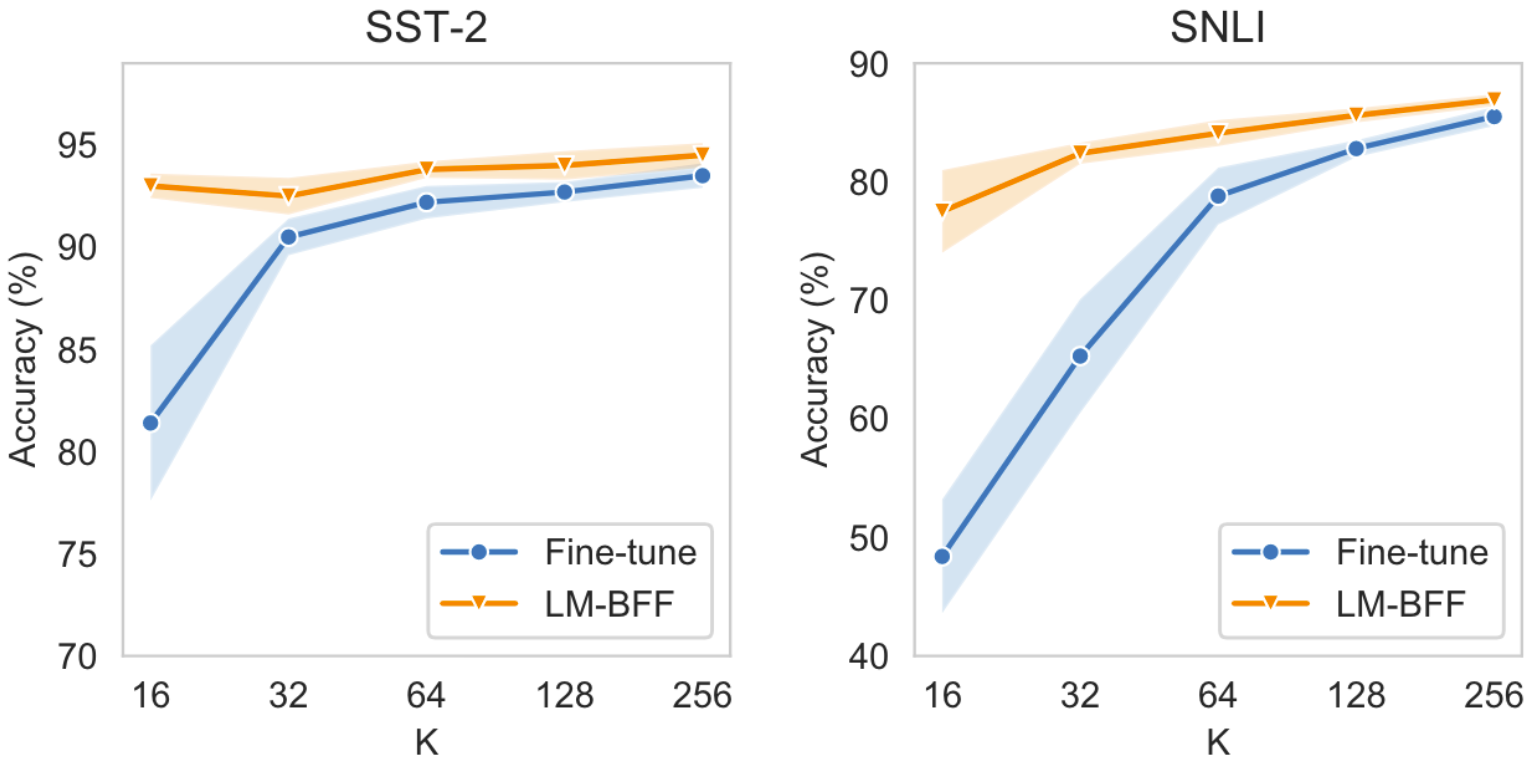
Standard fine-tuning vs LM-BFF with increasing K (# training examples per class).
There are, of course, limitations to our method. There is still large space for improvement in accuracy, and just like standard fine-tuning, LM-BFF is heavily affected by the large variance in few-shot training. Though the automatic prompt achieves on par or better performance than manual ones, it still requires some manual design (auto templates start from manual label words, and auto label words start from manual templates). Finally, prompt-based fine-tuning itself favors certain tasks that (1) can be posed as a “fill-in-the-blank” problem, (2) have relatively short inputs, and (3) do not contain many output classes. These are all open questions left for future work.
The paper was released at the end of 2020, and there have been lots of exciting advances about few-shot or prompting since then. Nevertheless, LM-BFF is unique in its study in automatic prompt generation and incorporating demonstrations in fine-tuning. Compared to recent soft-prompt approaches, LM-BFF (and other natural-language-prompt-based methods) has a vast advantage in smaller language models and few-shot scenarios. We hope that our work can inspire further exploration in this direction.
To conclude, in this post I discussed a lot of recent progress about natural-language prompts, soft prompts, and in-context learning, and introduced our LM-BFF paper. I believe prompting is a very promising direction in the years to come. In a broader context, prompt-based methods are about how to better mine the knowledge (about facts, reasoning, understanding sentiment, etc.) from self-supervised learning (pre-training), and efforts in this direction can help squeeze the potentials of LMs and make them better and better learners to our world.
Acknowledgements
Thanks Danqi Chen and Adam Fisch for proofreading the article and their helpful comments!